|
国内BGP-CEPH云服务器2核2G仅81元 赠送5G防御1个独立IP 50G固态硬盘 购买请进TOP云网站:https://www.zuntop.com/server/buy.html?lineid=1012 这款云服务器采用CEPH云存储技术,Ceph项目最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),并随后贡献给开源社区。在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像的后端存储。但是在2014年OpenStack火爆的时候、Ceph并不被很多人所接受。当时Ceph并不稳定(Ceph发布的第四个版本 Dumpling v0.67),而且架构新颖,复杂,当时人们对Ceph在生产落地如何保障数据的安全,数据的一致性存在怀疑。 随着OpenStack的快速发展,给Ceph的发展注入了强心剂,越来越多的人使用Ceph作为OpenStack的底层共享存储,Ceph在中国的社区也蓬勃发展起来。近两年OpenStack火爆度不及当年,借助于云原生尤其是Kubernetes技术的发展,作为底层存储的基石,Ceph再次发力,为Kubernets有状态化业务提供了存储机制的实现。 Ceph能够提供企业中三种常见的存储需求:块存储、文件存储和对象存储,正如Ceph官方所定义的一样“Ceph uniquely delivers object, block, and file storage in one unified system.”,Ceph在一个统一的存储系统中同时提供了对象存储、块存储和文件存储,即Ceph是一个统一存储,能够将企业企业中的三种存储需求统一汇总到一个存储系统中,并提供分布式、横向扩展,高度可靠性的存储系统,Ceph存储提供的三大存储接口:  1、CEPH OBJECT STORE对象存储,包含功能,特性如下: •RESTful Interface RESTful风格接口; •S3- and Swift-compliant APIs 提供兼容于S3和Swfit风格API; •S3-style subdomains S3风格的目录风格; •Unified S3/Swift namespace 统一扁平的S3/Swift命名空间,即所有的对象存放在同一个平面上; •User management 提供用户管理认证接入; •Usage tracking 使用情况追踪; •Striped objects 对象切割,将一个大文件切割为多个小文件(objects); •Cloud solution integration 云计算解决方案即成,可以与Swfit对象存储即成; •Multi-site deployment 多站点部署,保障可靠性; •Multi-site replication 多站点复制,提供容灾方案。 2、CEPH BLOCK DEVICE块存储,包含功能,特性如下: •Thin-provisioned 瘦分配,即先分配特定存储大小,随着使用实际使用空间的增长而占用存储空间,避免空间占用; •Images up to 16 exabytes 耽搁景象最大能支持16EB; •Configurable striping 可配置的切片,默认是4M; •In-memory caching 内存缓存; •Snapshots 支持快照,将当时某个状态记录下载; •Copy-on-write cloning Copy-on-write克隆复制功能,即制作某个镜像实现快速克隆,子镜像依赖于母镜像; •Kernel driver support 内核驱动支持,即rbd内核模块; •KVM/libvirt support 支持KVM/libvirt,实现与云平台如openstack,cloudstack集成的基础; •Back-end for cloud solutions 云计算多后端解决方案,即为openstack,kubernetes提供后端存储; •Incremental backup 增量备份; •Disaster recovery (multisite asynchronous replication) 灾难恢复,通过多站点异步复制,实现数据镜像拷贝。 3、CEPH FILE SYSTEM文件存储,包含功能,特性如下: •POSIX-compliant semantics POSIX风格接口; •Separates metadata from data 元数据metadata和数据data分开存储; •Dynamic rebalancing 动态数据均衡; •Subdirectory snapshots 子目录快照; •Configurable striping 可配置切割大小; •Kernel driver support 内核驱动支持,即CephFS; •FUSE support 支持FUSE风格; •NFS/CIFS deployable 支持NFS/CIFS形式部署; •Use with Hadoop (replace HDFS) 可支持与Hadoop继承,替换HDFS存储。 通俗点讲:Ceph提供了三种存储接口:块存储RBD,对象存储RGW和文件存储CephFS,每种存储都有其相应的功能和特性。 Ceph存储架构 Ceph 独一无二地用统一的系统提供了对象、块、和文件存储功能,它可靠性高、管理简便、并且是自由软件。Ceph 的强大足以改变贵公司的 IT 基础架构、和管理海量数据的能力。Ceph 可提供极大的伸缩性——供成千用户访问 PB 乃至 EB 级的数据。Ceph 节点以普通硬件和智能守护进程作为支撑点, Ceph 存储集群组织起了大量节点,它们之间靠相互通讯来复制数据、并动态地重分布数据。 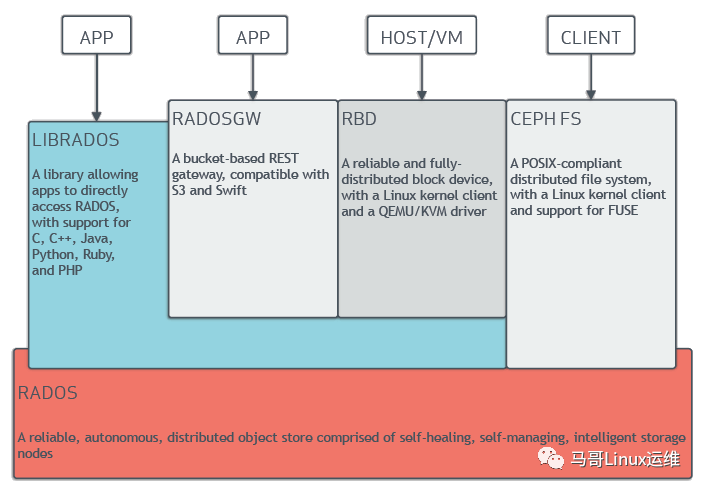 什么是Ceph分布式存储? 接下来,我们先来看一下Ceph的存储架构,了解Ceph的分布式架构,功能组件和涉及相关概念。Ceph分布式集群是建立在RADOS算法之上的,RADOS是一个可扩展性,高可靠的存储服务算法,是Ceph的实现的基础。Ceph有两个重要的组件组成:Ceph Monitors(Ceph监视器)和Ceph OSDs(Ceph OSD 守护进程)。 其中Ceph Monitor作为集群中的控制中心,拥有整个集群的状态信息,各个组件如OSDs将自己的状态信息报告给Ceph Monitor这个总司令,由此可以可知,Ceph Monitor这个总司令肩负起整个集群协调工作;同时Ceph Monitor还负责将集群的指挥工作,将集群的状态同步给客户端,客户端根据Ceph Monitor发送的集群状态信息可以获取到集群的状态,当集群状态有变化如OSD增加或故障时,Ceph Monitor会负责更新集群状态并下发给客户端。Ceph Monitor的重要不言而喻,为了保障集群的可用性,需要部署高可用,一般需要部署2n+1个节点,如3个或5个Ceph Monitor节点。 什么是集群的状态呢?Ceph Monitor中保存的集群状态根据其功能角色的不同,分为以下几个map状态表: •Monitor Maps,集群Ceph Monitor集群的节点状态,通过ceph mon dump可以获取; •OSD Maps,集群数据存储节点的状态表,记录集群中OSD状态变化,通过ceph osd dump可以获取; •PGs Maps,PGs即placement group,表示在OSD中的分布式方式,通过ceph pg dump可以获取; •Crush Maps,Crush包含资源池pool在存储中的映射路径方式,即数据是如何分布的; •MDS Maps,CephFS依赖的MDS管理组件,可通过ceph mds dump获取,用于追踪MDS状态。 除了Ceph Monitor之外,还有一个重要的组件是OSD,集群中通常有多个OSD组成,OSD即Object Storage Daemon,负责Ceph集群中真正数据存储的功能,也就是我们的数据最终都会写入到OSD中。除了Monitor之外,根据Ceph提供的不同功能,还有其他组件,包括: •Ceph Monitors(ceph-mon); •Ceph OSDs(ceph-osd); •Ceph MDS(ceph-mds),用于提供CephFS文件存储,提供文件存储所需元数据管理; •Ceph RGW(ceph-rgw),用于提供Ceph对象存储网关,提供存储网关接入; •Ceph Manager(ceph-mgr),提供集群状态监控和性能监控。 注:Ceph Monitor监视器维护着集群运行图的主副本。一个监视器集群确保了当某个监视器失效时的高可用性。存储集群客户端向 Ceph Monitor 监视器索取集群运行图的最新副本。而Ceph OSD 守护进程检查自身状态、以及其它 OSD 的状态,并报告给监视器们。存储集群的客户端和各个 Ceph OSD 守护进程使用 CRUSH 算法高效地计算数据位置,而不是依赖于一个中心化的查询表。它的高级功能包括:基于 librados的原生存储接口、和多种基于 librados 的服务接口。 Ceph数据的存储 了解完Ceph的架构后,我们先来了解一下Ceph的读写流程,期间会涉及到CRUSH,PGs等这些概念,我们从一个最基本的的概念入手:Ceph中一切皆对象,不管是RBD块存储接口,RGW对象存储接口还是文件存储CephFS接口,其存储如到Ceph中的数据均可以看作是一个对象,一个文件需要切割为多个对象(object),然后将object存储到OSD中,如下图: 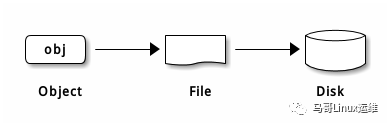 注:Ceph 存储集群从 Ceph 客户端接收数据——不管是来自 Ceph 块设备、 Ceph 对象存储、 Ceph 文件系统、还是基于 librados 的自定义实现——并存储为对象。每个对象是文件系统中的一个文件,它们存储在对象存储设备上。由 Ceph OSD 守护进程处理存储设备上的读/写操作。 那么,这些切割后的object怎么选择到对应的OSD存储节点呢,这需要依赖于Ceph的智能调度算法CRUSH,通过CRUSH算法将object调度到合适的OSD节点上,不管是客户端还是OSD,均使用CRUSH算法来计算object在集群中OSD的位置信息,同时保障object的副本能落到合适的OSD节点上,关于CRUSH算法的实现比较复杂,详情可以参考:CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data。 Ceph OSD 在扁平的命名空间内把所有数据存储为对象(也就是没有目录层次)。对象包含一个标识符、二进制数据、和由名字/值对组成的元数据,元数据语义完全取决于 Ceph 客户端。例如, CephFS 用元数据存储文件属性,如文件所有者、创建日期、最后修改日期等等。 object调度到OSD节点上,如果一个文件发生了变动或OSD出现了异常,以一个100G的文件为例,每个object默认为4M,将会切割为25600个object,如果Ceph集群需要正对每个object都进行调度的话,可想而知,在一个大规模集群中,crush的调度将会变得异常的繁重。因此,Ceph引入了另外一个概念PG,PG是Place Group即放置组,可以简单理解为一个装载object的容器,object将映射到PG中,PG最终会调度到某个具体的OSD上,因此CRUSH由object调度转为PG的调度,而PG的数量是相对固定的,因此集群分布时调度相对没有那么繁重,同时,当某个OSD异常时,CRUSH调度算法只需将其上的PG调度至其他OSD上(而不是将其上的object进行调度)。Ceph的整个数据调度写入流程如下图: 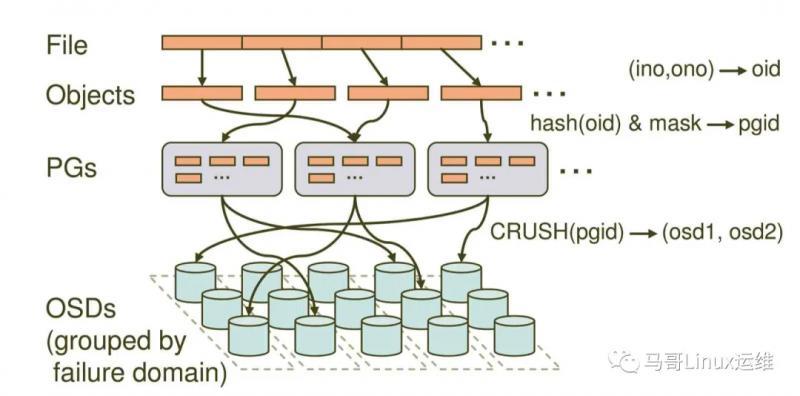 •一个文件将会切割为多个object(如1G文件每个object为4M将切割为256个),每个object会由一个由innode(ino)和object编号(ono)组成oid,即object id,oid是真个集群唯一,唯一标识object对象; •针对object id做hash并做取模运算,从而获取到pgid,即place group id,通过hash+mask获取到PGs ID,PG是存储object的容器; •Ceph通过CRUSH算法,将pgid进行运算,找到当前集群最适合存储PG的OSD节点,如osd1和osd2(假设为2个副本); •PG的数据最终写入到OSD节点,完成数据的写入过程,当然这里会涉及到多副本,一份数据写多副本。 好了,现在我们对Ceph有了基本认识了。后面我们讲继续了解Ceph伸缩性和高可用性;动态集群管理;纠删编码;缓存分级等内容。当然、我们也会具体了解到如纠删编码中关于读出和写入编码块,被中断的完全写等更细的内容。 |




2021年4月10日,金丰集团与韩国亚拓士及浙江旭玩达成战略合作,...详情
正统新派回合手游《大秦帝国OL》全新版本即将来袭!新装备、新玩...详情
每个人心中都装着一个明星梦!时光荏苒,回头一看,愕然发现你心...详情
2021年4月10日,金丰集团与韩国亚拓士及浙江旭玩达成战略合作,浙江旭玩将所获得《传
每个人心中都装着一个明星梦!时光荏苒,回头一看,愕然发现你心中的明星梦已经向现实
正统新派回合手游《大秦帝国OL》全新版本即将来袭!新装备、新玩法即将震撼登场!传说中









请发表评论